
Hello and welcome!
In today’s blog, we will be continuing the subject of mapping and enumerating applications to extract information. We will be learning the following in today’s blog post:
- Discovering hidden parameters, pages, and files
- Identify Entry Points for User Input
- Identify Server Side Technologies
- Mapping the Attack Surface
Discovering Hidden Parameters, Pages, and Files
Hidden parameters are parameters in HTTP requests that are designed to not be seen by anyone that are checking the requests themselves. Parameters are the variables inside the HTTP request or URL itself that the server uses to complete tasks such as search variables, user credentials, cookies.
Hidden files are the same concept as the parameters, but they are files stored on the server that is also designed not to be seen by normal users – usually, these are files that the developers of the site have forgotten to remove which can display key information about the server-side functionality.
Hidden pages are webpages that are also designed to not be seen by normal users (any user that is not authorized to see it). These pages can be login pages, debugging pages that were neglected by the developers, and never taken down. All of these hidden entities show something in common with each other, they are hidden because there is important information that they can reveal to a hacker that has access to them.
Tools and Methods to Discover Hidden Content
In my earlier blogs, I discussed using Burp Suite as my go-to for brute-forcing directories and other content. I have recently just learned about a proxy tool called OWASP ZAP which is another version of Burp Suite – but every feature that it offers is FREE. Most features that I needed on Burp Suite are only accessible through the paid version such as automated spidering, using more threads when brute forcing directories so it completes it much quicker, and more. In the ZAP tool, there are various tools we can use when attempting to discover hidden content. With that being said, lets dive into some of the steps we can take to discovering hidden content:
Steps for Discovering Hidden Parameters
1. Brute-force the URL to find as many directories you can – analyze the naming scheme the URL uses and match it up with word-lists that use the same naming scheme like all lowercase letters, dashes that are used for spaces, camel-casing, etc. – Use the OWASP ZAP tool to attack the directories by right clicking the website found in the tool > attack > Forced Browse Directory (and children) > at the bottom of the screen a new tab will show up for you to input the wordlist you want to use.
2. Use common debugging parameter names when trying to discover hidden parameters – you’ll be surprised as to how much stuff you will find – you can use common names like (debug, test, hide, source) and also common values like (0, 1, false, true etc.) there are many word lists on GitHub pertaining to these fields which you can use.
3. Observe closely the responses you are getting from the website – look at the response code, length, the time it takes for each response, and the content of each response itself – check my previous blog post pertaining to the different response codes. For example, you get a bunch of 404 responses that are all the same, but in one of the requests you see a redirected response (302) because you are not authenticated to see a particular webpage – this is a great finding that should definitely be investigated further.
4. Target a number of different pages or functions when discovering hidden parameters. Try to choose functions that are most likely that developers have implemented debugging logic like login pages, search functions, file uploads/downloads
There are a ton more methods that can help you discover hidden content, but this is just a starting guide to get you to understand the process and how it works.
Checkout some tutorials on hidden content discovery through using the ZAP tool here: Web App Penetration Testing – Discovering Hidden Files with Zap
Identify Entry Points for User Input
Entry points for user input are very important to keep track of. These are not only entry points for user input, but also entry points for attackers to get in control of websites. The fact that users are able to provide input to a website leads to a whole set of vulnerabilities developers have to prevent (or hopefully- they try to prevent). With users inputting different pieces of text – this can lead to cross site scripting (XSS) vulnerabilities. These are the key locations to pay attention to for entry points:
- Every URL string up to the query string parameter
- Every parameter submitted within the URL query string
- Every parameter submitted within the body of a POST request
- Every cookie
- Every other HTTP header that the application might process – in particular the User-Agent, Referer, Accept, Accept-language, and Host headers
Name Conventions of URL Parameters
In URL file paths, applications that use REST-style URLs, the parts of the URL that precede the query string, can in fact function as data parameters and are just as important as entry points for user input as the query string itself. For example:
https://prepareanywhere.com/browse/products/tshirtsThe strings, products and tshirts should be treated as parameters that store information for the search function.
Some applications do not employ the standard name=value format for these parameters – the can employ their own convention or syntax of query strings. For example:
/somedir/somefile;foo=bar&&foo2=bar2
/somedir/somefile;foo=bar$foo2=bar2
/somedir/foo.bar/somefileIt is crucial to detect these non-conventional parameter formats, as it will affect your findings when mapping out the web-app.
HTTP Headers
The HTTP headers are always important to look at when searching for points of entry. For example, we can spoof the User-Agent header to act like we are on a mobile device so the server responds to us with the mobile layout instead of desktop. This can help us get a point of entry if the mobile layout is not properly secured like the desktop version. There may be different inputs that are not sanitized properly which we can take advantage of for XSS.
We can carry out an attack that performs a GET request spoofing the user agent string and see how the server reacts to it. Based off of the results, we can act from there to continue with our findings.
We can also supply other headers that the application does not usually process – but still processes. Supplying different headers than what the server normally handles can reveal information about the behavior of the server.
Identify Server Side Technologies
Identifying server side technologies is crucial when mapping an application. You need to know what technologies the server runs on, the hardware, operating system, file types, etc. Identifying these key attributes about a server will help find more ways to perform attacks on the server and gaining access to it.
Banner Grabbing
Many web servers disclose fine-grained version information, both about the software it is running on and other components that have been installed. Banner grabbing is the process of gaining information from a machine by querying in a service port.
Banner Grabbing with Netcat
Below is going to be a quick example of grabbing a banner from an IP to gain information as far as what the server is running on. The following command will produce a banner grab:
nc -n -w1 -vv 35.227.24.107 80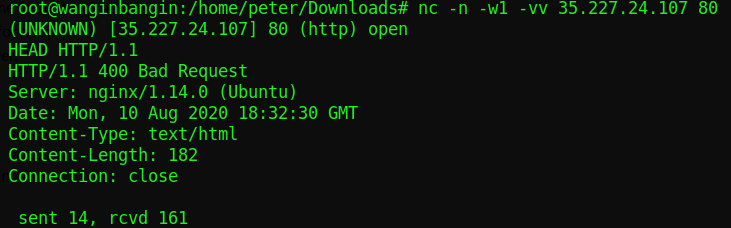
Note: we had to type in the command: HEAD HTTP/1.1 to get the HEAD of the HTTP request once we connected via netcat. From the information above, we see that the server is running on Ubuntu nginx version 1.14.0. Just from this information alone, we can check whether if that version is outdated and what vulnerabilities it holds.
File Extensions
File extensions that are used within URL often disclose the platform or programming language used to implement relevant functionality. You can use automated content discovery techniques already described in this blog as well as part 1 of this blog. We can also find out what file extensions the servers are using by producing error messages. Some applications output verbose error messages that may pertain to a particular programming language and reveal some back-end schemes.
Directory Schemes
In the URL, you can encounter subdirectory names that indicate the presence of an associate technology. For example:
- serverlet – Java serverlets
- pls – Oracle Application Server PL/SQL gateway
- cfdocs or cfide – Cold Fusion
- SilverStream – The SilverStream web server
- WebObjects or (function).woa – Apple WebObjects
- rails – Ruby on rails
There are many more, but you get the idea!
Session Tokens
Many web servers and web app platforms generate session tokens by default with names that provide information about the technology in use. For example:
- JSESSIONID – The Java Platform
- ASPSESSIONID – Microsoft IIS server
- ASP.NET_SessionId – Microsoft ASP.NET
- CFID/CFTOKEN – Cold Fusion
- PHPSESSID – PHP
Steps For Identifying Server-side Technology
1. Identify all entry points including URLs, query strings parameters, POST data (data in body), and HTTP headers that hte application processes
2. Find out whether the query string uses a standard format and figure out how parameters are being transmitted
3. Get the HTTP banner of the site. Note that in some cases, different areas of a web application are handled by different back-end components which means there will be different server headers
4. Find any software identifiers contained within any custom HTTP headers or HTML source code comments
5. Research the software versions of those web servers and identify any vulnerabilities that can be exploited
6. Review the URLs once again to identify file extensions, directories, or sub-sequences that can provide clues about the technology on the server
7. Review the session tokens issued by the application and find what technologies are being used
Conclusion
In this blog we learned various methods of discovering hidden content, mapping out web server technologies, identify user input entry points, and so much more. With pentesting any application, it is very similar to a puzzle that is being presented to you. You want to find out everything about that particular puzzle, how it works, how its functions are carried out between the server and client. Gaining as much knowledge about the application is crucial in forming your attack methods.
Thank you for reading with me today and I will catch you all next week,
Peter